And now for something completely different….
I wanted to share some details about a vitural conference I attended this past week called hack.summit(). https://hacksummit.org/ This wholly online conference is in its second year and is a good resource for people who would like to attend a conference and take advantage of some Q&A and workshops with leaders in our field. The cost for registration is mostly free, either a share on social media or a small donation
I attended the debut session of hack.summit() in 2014. The format is a combination of talks, Q&As and short workshops. One of the more memorable ones for me last year was an hour long session building a coffee shop locator from scratch in about an hour. Link
Here’s a short summary of the sessions I attended this year:
Floyd Marinescu – CEO of InfoQ.com – This session consisted mainly about how to establish suitable cultures for virtual teams, meaning teams that aren’t necessarily bound to the same office but must collaborate on projects from separate physical locations. There are suggestions around patterns and the myriad of tools that are available to virtual teams. This was interesting as I’m already working on a virtual team covering at least four separate locations. Additionally, there was mention of InfoQ and a recommendation to spend some time there to read up on current issues and have an opportunity to collaborate with others.
Kent Beck – Created Extreme Programming, created TDD, co-created Agile, authored 9 books – It’s ironic that this talk was the day before a half-day lunch and learn my team had on TDD and Dependency Injection. TDD is not a new paradigm but understanding the need for unit tests and structuring your code so that it’s testable on a granular level is vital for long term supportability of your codebase, especially if you’ve got multiple individuals working in that code base and for any inheritors of your code. I’m sure we’ve all inherited examples of stale (yet production) code with documentation with multiple birthdays and wish we had at least some insight as to why certain sections of code even exist.
Gregg Pollack – CEO, Codeschool – This was another ‘soft skills’ session presented by the CEO of Codeschool (recently acquired by Pluralsight) titled ‘ The Developers Path to Success and Winning’. This was a general discussion of components that would help you build a successful career as a developer, including how to seek out a mentor, attending meetups and conferences, knowing what’s important enough to demand your attention (being deliberate about your work and learning), how to seek out work to stretch yourself, etc.
Janet Weiner – Engineering at Facebook, big data expert – Open Data Challenges at Facebook – I’ll admit that the bulk of this talk was way over my head. Overall, it was a case study on how data availability presents problems as it scales to unprecedented quantities, using Facebook’s architecture as an example. While I’m not very familiar with ‘Big Data’ yet, it’s definitely on my radar as something to become familiar with in the near future. This was a good example of a presentation showing me exactly how much I don’t know!
Mostly I enjoyed the ability to attend virtually and the ability to go back as needed to cover things I might have missed. If you’d like to register and access the content, it’s not too late! All you’ll need to is go through the registration process at the hack.summit() website and you’ll have access to all of the talks and reference materials.
If any of you is curious about (or may have attended) hack.summit() 2016 or have any questions or comments, please feel free to add them here or address them to john@benedettitech.com.
Thanks for looking in!
Creating a Github Repo
So, this week I created a Github account for Benedetti Tech. For those of you that are not familiar, Github is a web based repository for open source projects with tools for source control, issue tracking and collaboration with other open source developers. It’s become popular enough that you might count on potential employers to look for any accounts associated with your name in order to evaluate you for work, whether you invite them to or not. This isn’t to say that you MUST have an account to be taken seriously for employment, only that it’s another option and opportunity to grow and showcase your skills with others in the industry. Full disclosure: I barely use my personal Github account and yet have somehow managed to remain gainfully employed.
As part of creating a new Github account, there’s an invitation to a simple ‘Hello World’ walkthrough located at https://guides.github.com/activities/hello-world/ This article will focus on a walkthrough of that guide.
Step 1 is to create a new repository using your Github account. Although reasonable people may differ as to what a repository should equate to, I use the term ‘single codebase’ to refer to a single repository. A codebase can consist of multiple apps, integrations or services. The idea here is to have a single logical grouping of code (and hopefully tests and documentation) with which to associate with a history of issues/stories and commit history. This can help users or inheritors of your code to gain insight into the history of an application that might prove helpful when trying to understand the intent of said codebase.
It’s a pretty simple step, from the Github console, click the + then New Repository link.

Now that we have our newly minted repository, the next step is to create a branch. Usually you’ll have a master or main line codebase that should be a representation of what’s in production. Branches represent code in development may eventually make it into the production code. Each branch will have its own history of commits and the capability to annotate them or roll them back as needed.
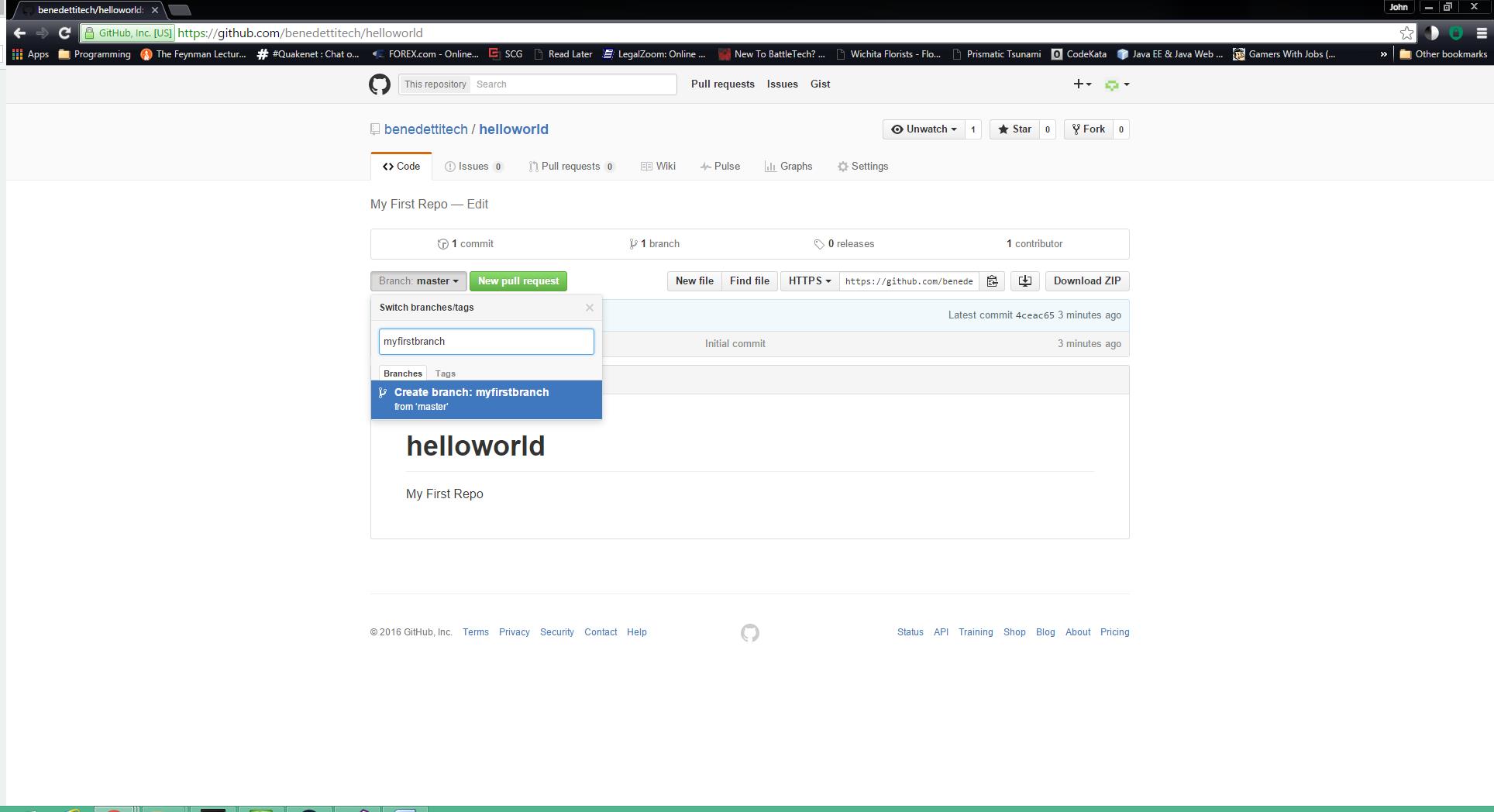
To create a branch, click on the branch dropdown. A dialog will appear where you can type in a new branch name and then you can click Create. Once you’ve created the branch, the console will automatically switch to your new branch as your current branch.
Now that you have your new branch, it’s time to make some changes and commit them. The way the Github orientation suggests doing this is by editing the Readme file via the console. I’m going to take this outside the box a little bit and install Github Desktop. This is a GUI console you can keep on your desktop with which to manage local copies of your repositories (that you will eventually be developing on locally). The link to download is https://desktop.github.com/ and the app is available for Windows or Mac. I’ll be installing the Windows version.

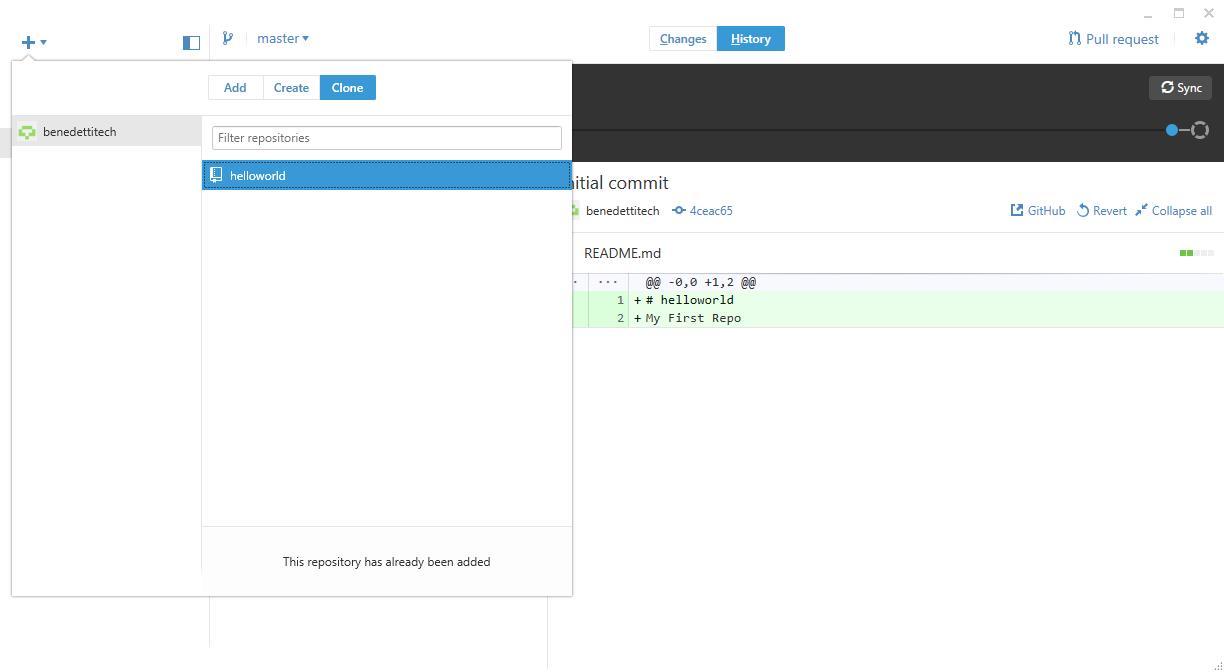
After I’ve installed Github Desktop, I can clone the repository I’ve just created by clicking the + sign and Clone.
First, I’ll select a directory where the local clone will reside. Then, I’ll open the Readme.md file and make some changes as the walkthrough suggests.
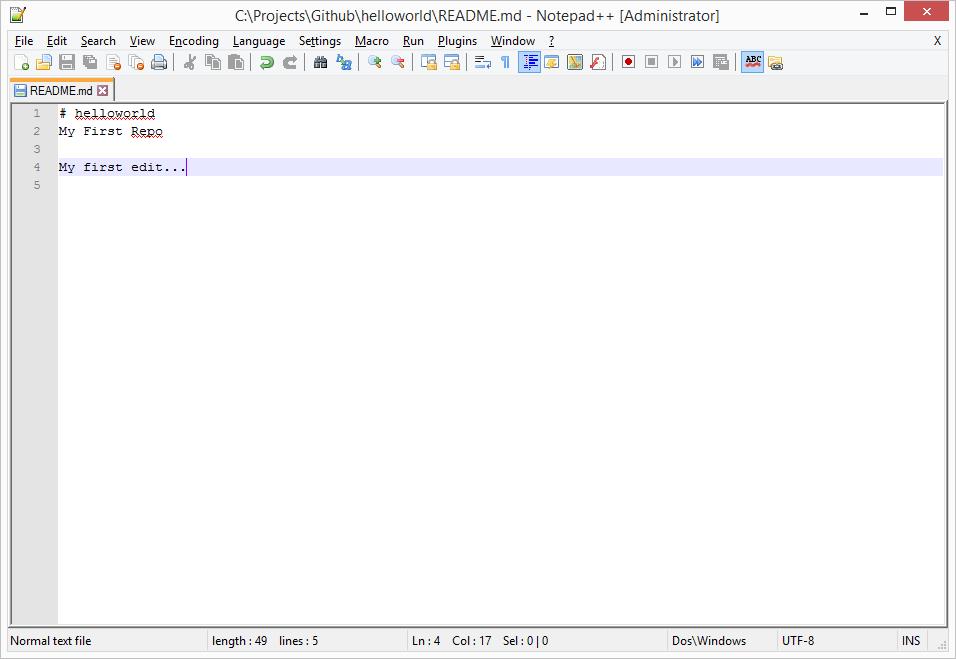
After saving my changes, I’ll go back to Github Desktop and see if it’s detected my changes. And it has! Now I’ll add a Summary to the changes (Always try to make these detailed!) and then commit the changes to the branch.
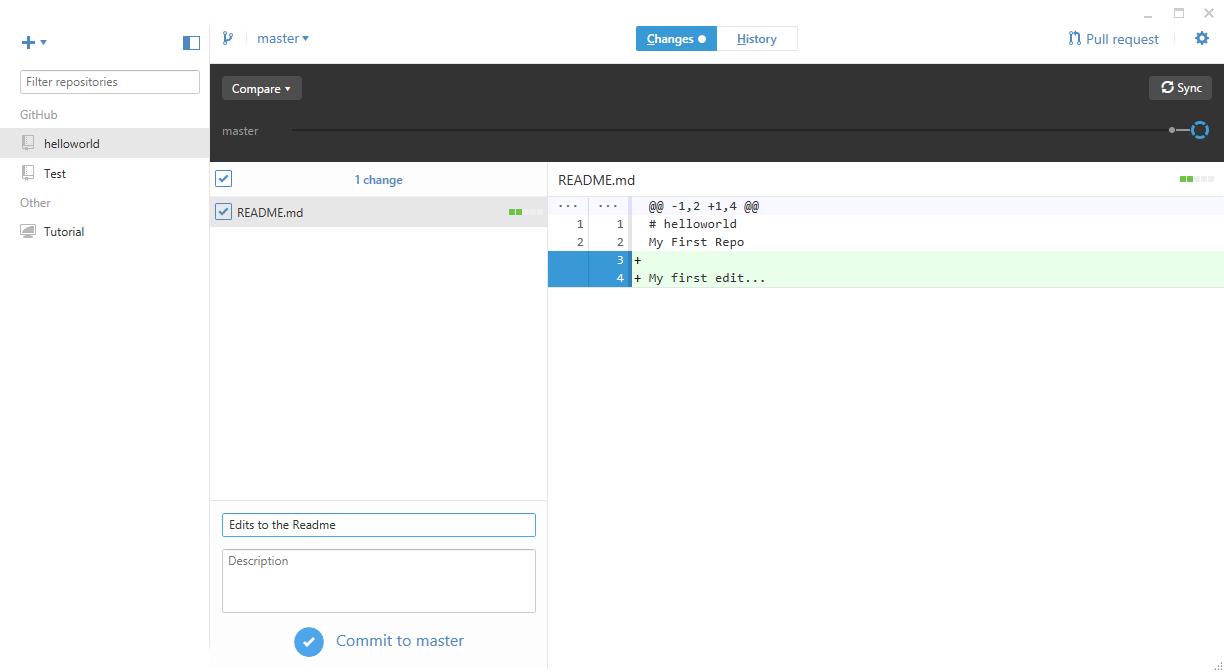
The next step in the walkthrough is to create a Pull Request to merge the branch back into the master. You’ll have to excuse the additional merge commit as I initially made my changes to the Readme in the master instead of the branch. Let this be a lesson to always ensure you’re working in the correct branch!
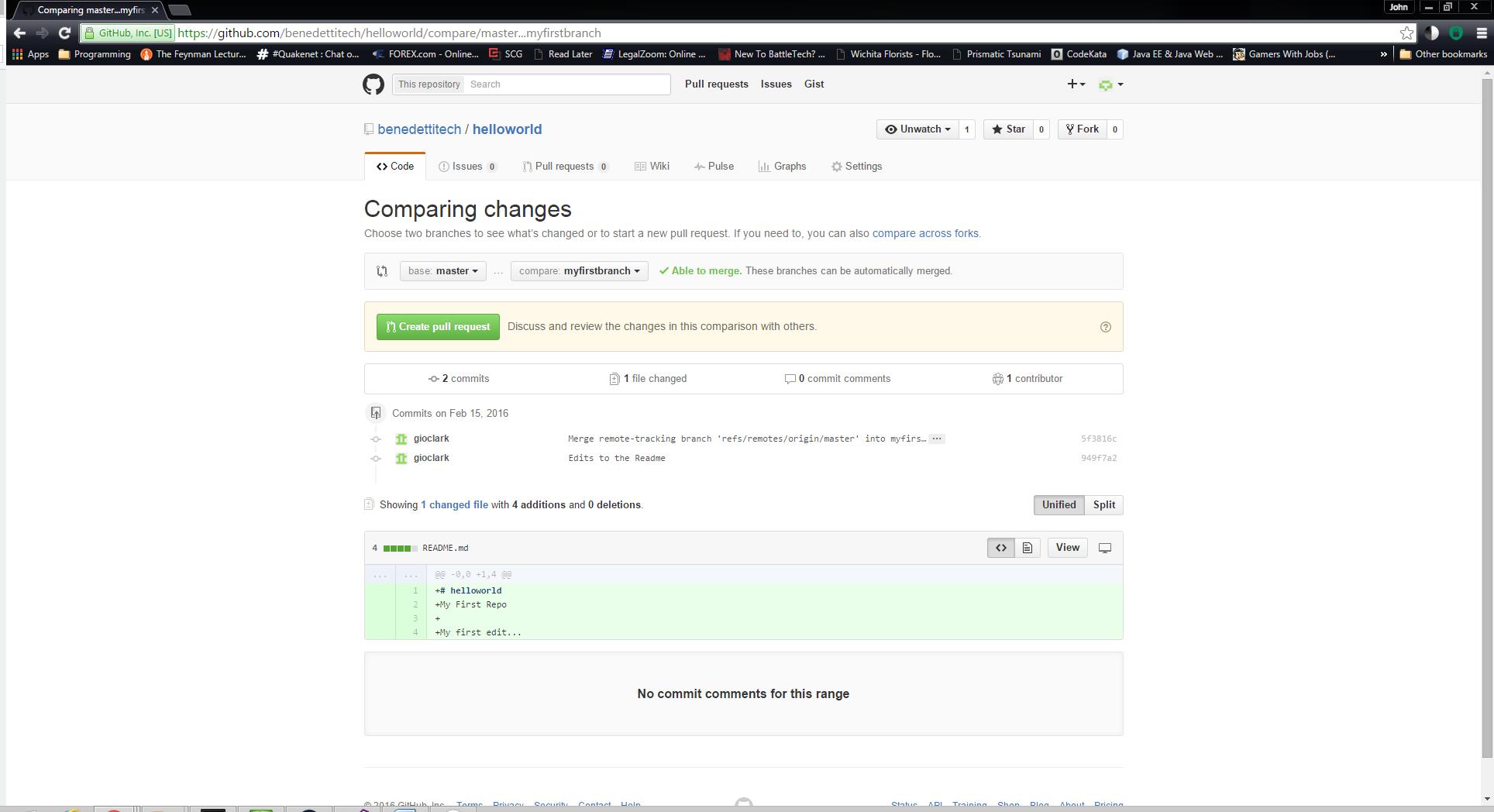
After I’ve reviewed the commits, I’m ready to create the Pull Request itself. Give it a title and some decent notes and then click the Create Pull Request button.
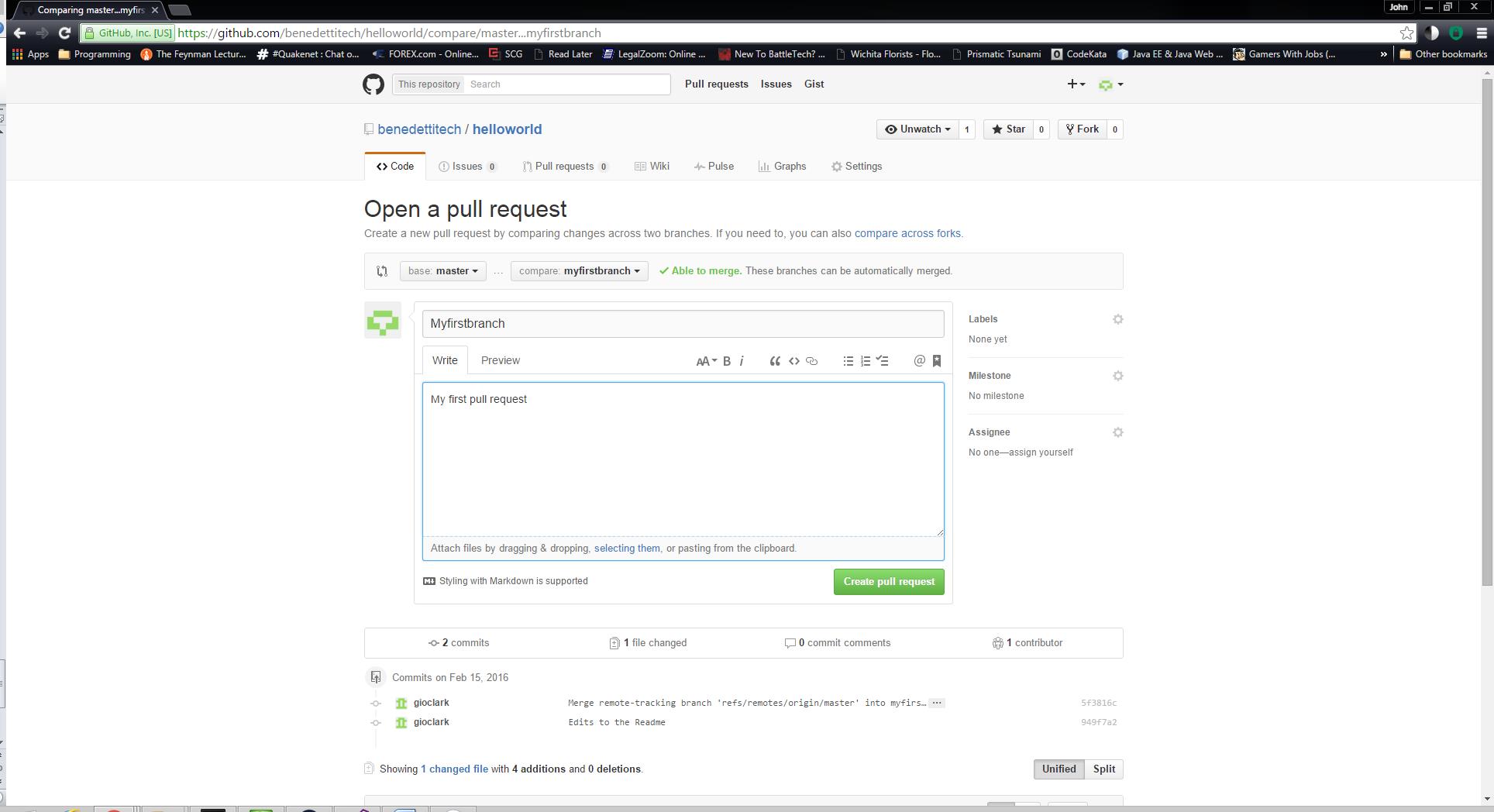
Now that I’ve created the Pull Request, the request will need to be reviewed and either merged to master, or possibly denied and returned with comment. Ideally, this should be done by someone who is reviewing the code and evaluating its possible benefit or impact to the codebase. Think of it as an in-line code review. Either way, this process is at the heart of collaboration around these projects whether working with a team at the same business or hacking in your own free time.
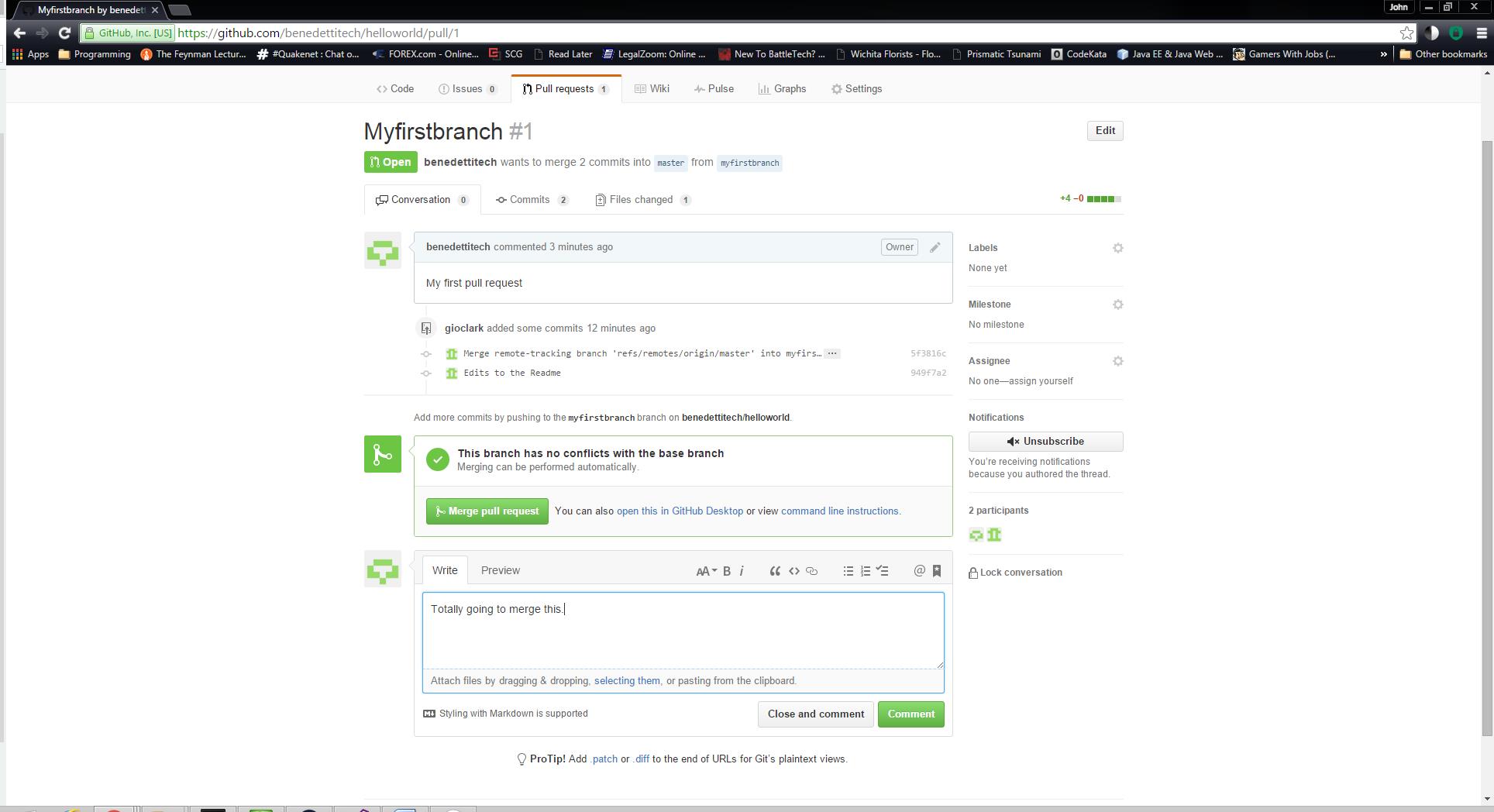
Once it’s been reviewed, I’ll comment and click Merge Pull Request. If there are no conflicts, you should get a confirmation message. That’s it! I’ve created my first repo and walked through the basic steps of branching, committing and merging.
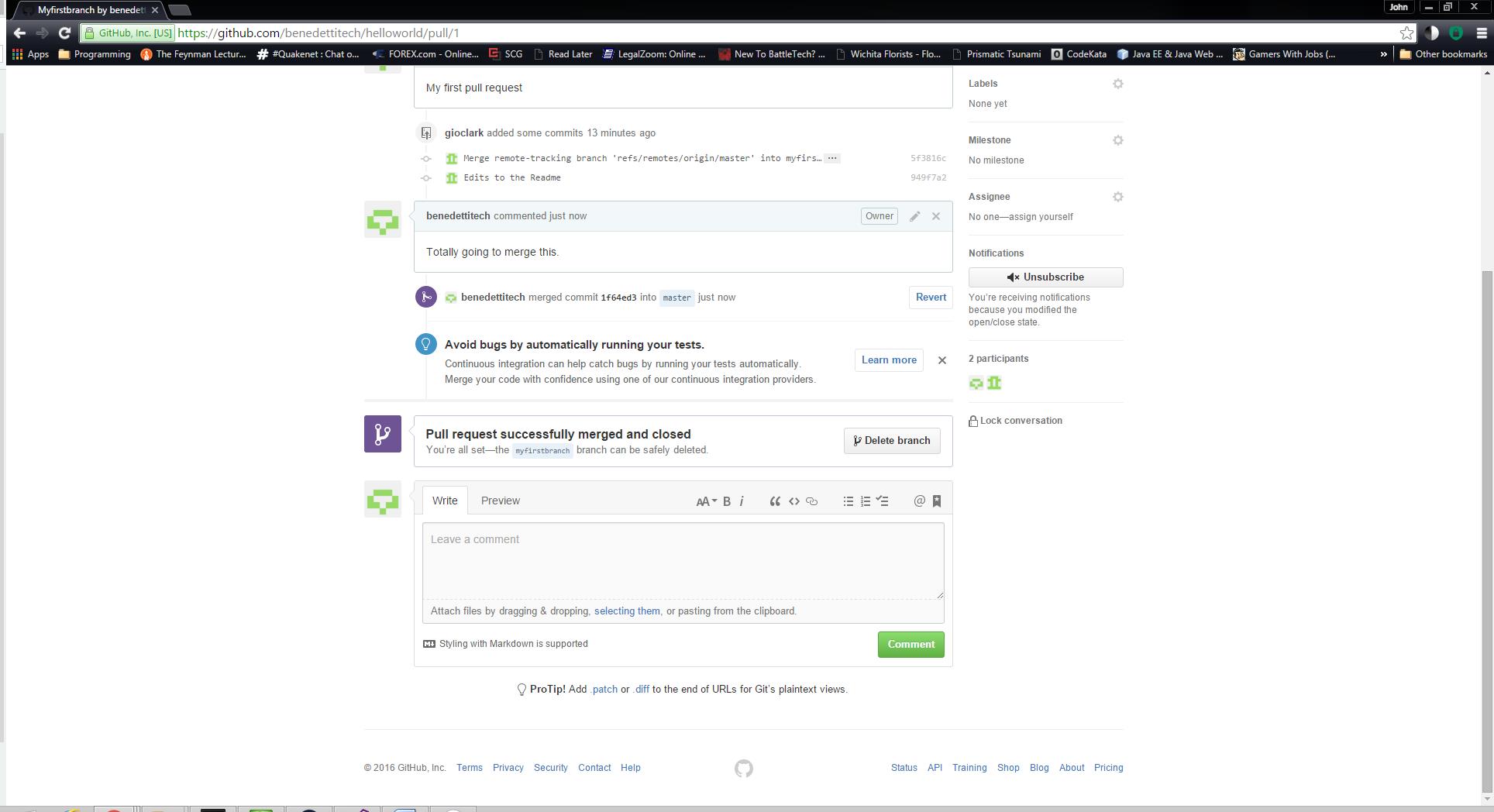
I’m interested in hearing about your opinions and experiences with Github and I would invite you to follow my account there. Additionally, I’d be happy to hear about what you’re working on and see if there are any opportunities for collaboration or even just sharing knowledge. Please do feel free to follow Benedetti Tech on Github and invite me to do the same!
If any of you have suggestions around Github or have any other questions or comments, please feel free to add them here or address them to john@benedettitech.com.
Thanks for looking in!
Deploying a project to Azure
First, I’ll create the Web API project. Since the article actually called for creating the resources inline with the project creation, I’ll actually skip the step where we create the Azure app itself. Instead, I’ll just connect to the resources that are already there once the project is created.
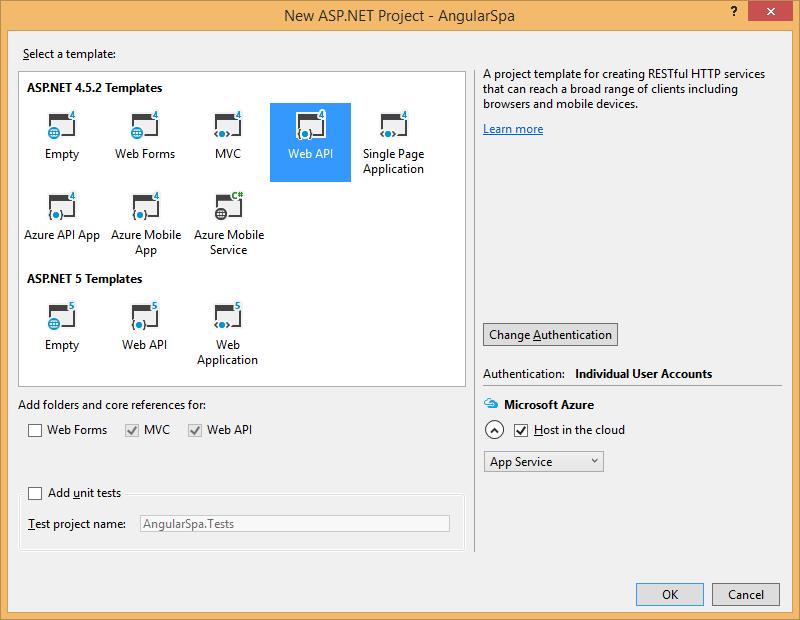
Second, I’ll install the Angular SPA package outlined in the article. I am a complete Angular noob but am looking forward to tinkering with the framework as a lot of developers I know make great use of it. Angular will install several dependencies such as jQuery. Once this is installed, you can move on to the publishing step.

Lastly, we’ll actually publish the newly created app ‘To The Cloud’. You’ll go to the Publish dialog for your project and select Azure App Service to create a publishing profile. I’ll look for the web app node previously created and ensure that it’s available for publishing.

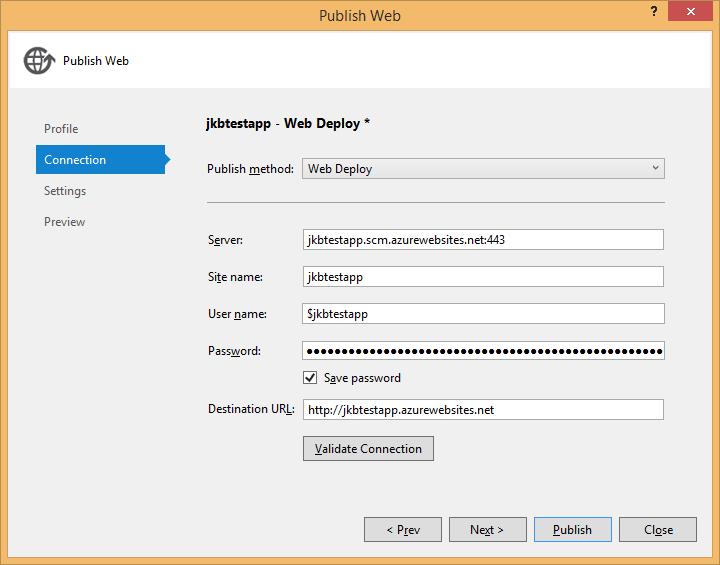
Then I’ll add the connection criteria for the SQL database. Please note, you will need to go into the Firewall settings for your Azure SQL Server and add your client IP in order to use SSMS or another tool to connect directly to the DB. This includes the dialog for setting up the connection string for the app. Once all your settings are in place, you can click Publish.
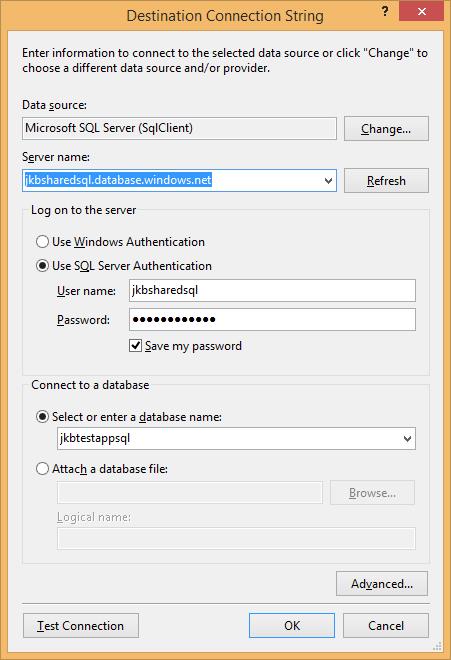

The publish may take a short while but once it’s complete, you can then navigate to the site and see the results. If you’d like to take a look at mine, you can find it at http://jkbtestapp.azurewebsites.net/welcome
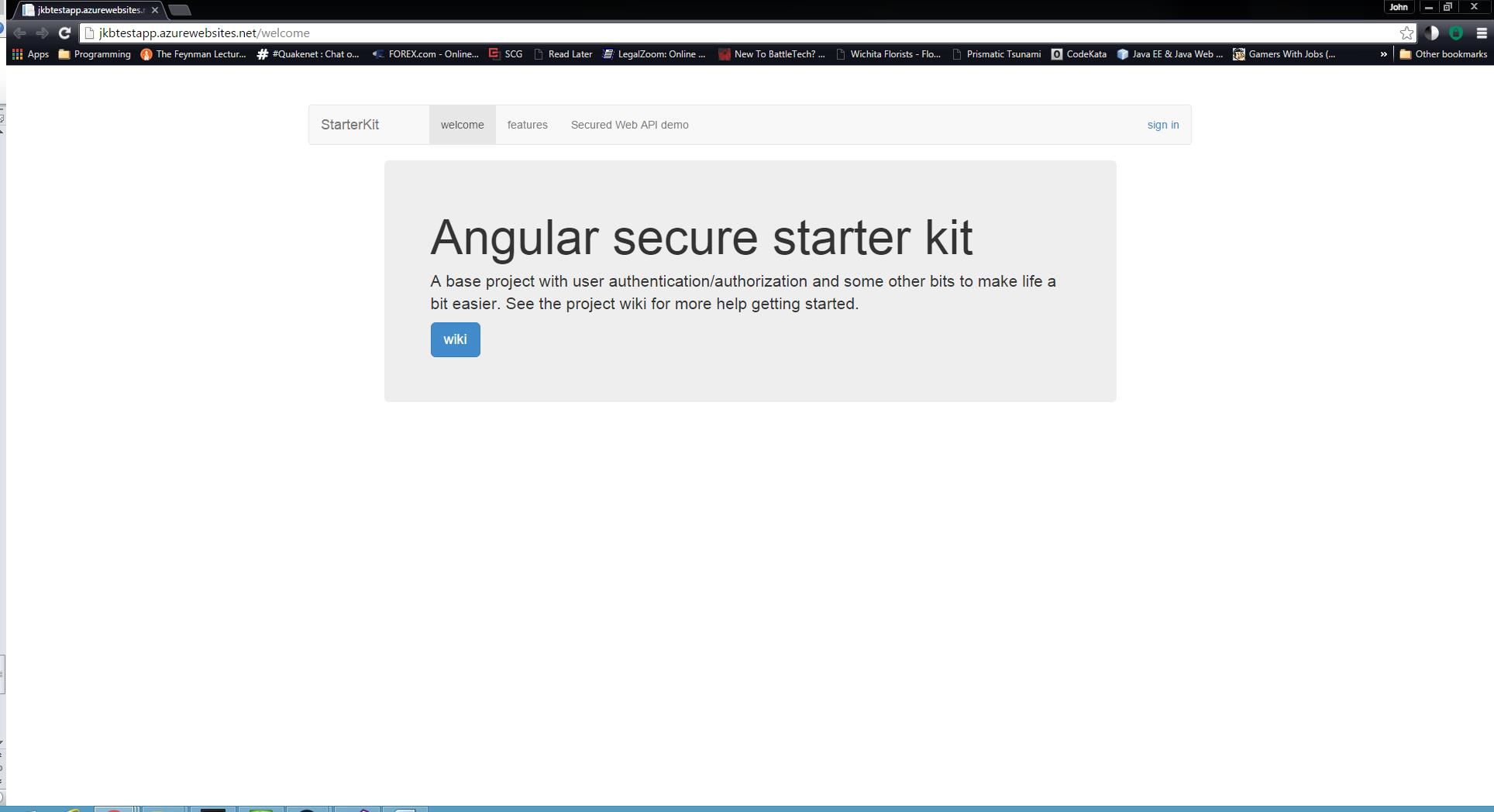
As you can see, once you get the hang of standing up the basic PaaS components, it’s very easy to deploy to an Azure environment. If any of you have suggestions around deploying to Azure or have any questions or comments, please feel free to add them here or address them to john@benedettitech.com.
Thanks for looking in!
How to Provision an Environment in Azure
It’s been a while since I’ve posted so I do apologize for the lag. I’ve been doing some experimenting with Azure in my RL job and I’d like to share a couple of lessons learned with provisioning and deploying to Azure.
I was looking for an outline on simple deployments and found a quick walk-through at Useful Development Blog. Using this outline, I’m going to provision an environment and deploy a simple web app to Azure.
The prerequisites noted in the article are as follows:
* Visual Studio 2013 (Update 3+)
* The Azure SDK (you can get that here or use the Web Platform Installer)
* an account with Azure
I’m going to use the tools deployed previously to accomplish the same tasks. The only difference should be that I’m using Visual Studio 2015 Community rather than 2013. Also, i’m going to provision my environment FIRST prior to deployment. While you can automatically let Visual Studio create the necessary Azure nodes automatically in order to host your app, I feel that it will be necessary to know exactly what I’m provisioning and how much it will cost.
After reviewing the article, it looks like I’ll need a Web App node as well as a SQL database for the backend. In order to put all of this together, I’ll want to create the following resources:
* Azure Resource Group – This is a logical grouping of managed resources. It makes it easier to organize your nodes and identify which are related and dependent on each other. Also, in the event of any relevant notifications from Microsoft about impacts or changes to a region, you’ll want to know which one your resources are in.
* Azure Storage Group – This is a shared storage pool that can be used by any of your Azure nodes that require it.
* Azure Virtual Network – This isn’t truly required since we won’t be doing any network design or provisioning, but some of the nodes will require that one be set.
* SQL DB + DB Server – These will be PaaS (Platform as a Service) nodes to host my database.
* Web App – This will be another PaaS node to host the actual app.
I’ll begin by logging into the Azure portal and creating the Resource Group. You do this from your portal dashboard and clicking Resources Groups in the left sidebar then Add. Choose an appropriate name, which subscription you want it to belong to, and where you want the Resource Group to be located. The location may be relevant depending on where your customer base is for purposes of latency, etc.

Once the resource group is created, I’ll want to create a Storage Group. It can be more economical to use a shared storage group rather than many individual storage groups for each node. Additionally, you have more options for selecting the redundancy/fault tolerance of the storage as well as options for speed, etc.
To create the storage group, navigate to the Resource Group and click Add. A search window will pop-up where you can search for any of the myriad of nodes available in the Azure catalog. Select Storage Account and when prompted select Resource Manager for your deployment model and click Create.


You’ll be prompted for the parameters to be used for your storage account. I will pick Locally Redundant and disable Diagnostics. Also, I’ll be selecting the Resource Group created in previous steps. When selecting your storage parameters, the amount listed for pricing is per month/100GB. You should only be charged for what you actually use so the cost should be pro-rated for the month.

Next, I’ll create the Virtual Network. Follow the previous steps of navigating to your Resource Group and clicking Add. This time, type Network for your search criteria and select Virtual Network. As before, select the Resource Manager option and click Create.
For my parameters, I’ll be choosing an appropriate name and selecting my existing Resource Group and Location. Once this is selected, click Create.

The next step, creating the SQL Server and DB, will be a bit more complicated but will follow the same basic pattern. As before, go to your Resource Group and click Add, then use SQL as your search criteria. The type of node you’ll select to create will be SQL Database. Once you’ve selected that option, click Create.

Inside of the SQL Database create panel, you’ll have an option to select your Server. Since we don’t have a server yet, our first step will be to create one. Click in the Server panel and then select Create a New Server. When creating a new server, you’ll choose an appropriate SQL Server name as well as creating your SA Account and password. You’ll also select a location for the node.


Now that we have our Server, we can finish creating our DB. You can select an existing DB backup to map from or even use the sample Northwinds database. I’ll be selecting Blank DB for this example. There are a large number of pricing options to choose from for your DB performance and sizing options. Select the one that’s most appropriate for your app. Your subscription and Resource Group options should auto-populate. Once you’ve selected your options, click Create. The SQL DB creation takes a few minutes.
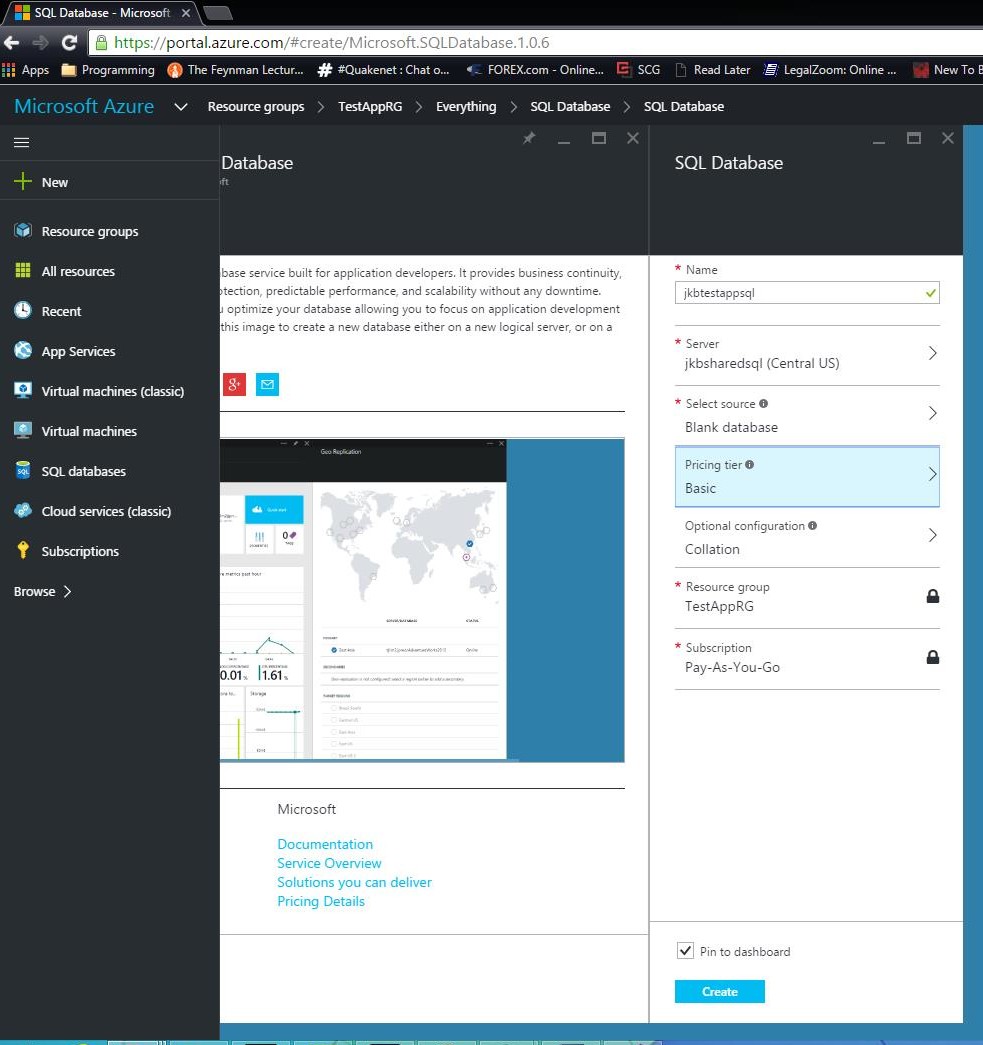
Lastly, we’ll need to provision a Web App node to host the actual app. Again, from your Resource Group, click Add and use Web App for your search criteria. Select the Web App option and click Create.

Once inside the creation dialog, you’ll choose an appropriate name for your app as well as confirm that your subscription info and Resource Group is correct. The last thing you’ll do is select a Service Plan. This is a configuration that can help you standardize your pricing and performance expectations for multiple apps. If you’re doing large scale or automated deployments, these can be useful to have for future tasks.
Under App Service Plan, click Create New. Inside of the App Service plan creation panel, choose an appropriate name for the plan. Under pricing options, you have various levels of availability and performance. Select the one most appropriate for you. Again, rates are for the month and pro-rated for actual usage. So, if you take your app down periodically or only need the services available at certain times, you can bring them down in the Azure portal and you should save that cost.

If you’ve completed all the above steps, then congratulations! You’ve successfully provisioned your first Azure environment and are ready to deploy an app!
My next post will cover the creation of the project as well as the deployment steps. If any of you have suggestions around provisioning in Azure or have any questions or comments, please feel free to add them here or address them to john@benedettitech.com.
Thanks for looking in!